attention ⁉️ How to write attention module in transformers By Pengpeng Wu Posted on November 20, 2025 ⚙️ 记录一下transformers中的Llama是怎么写attention的,并介绍如何无侵入式修改Llama为双向Llama,并取消RoPE旋转位置编码 [Read More] Tags: huggingface
compute_metrics 📚 compute_metrics in Trainer By Pengpeng Wu Posted on November 19, 2025 ⚙️ 介绍传入Trainer的compute_metrics函数中EvalPrediction.predictions和EvalPrediction.label_ids分别是什么? [Read More] Tags: huggingface
scRNA_LLM 🎉 Pretraining a scRNA LLM from scratch By Pengpeng Wu Posted on November 16, 2025 🚅 大概今年的3-4月份,我尝试自己从头预训练了一个单细胞转录组大模型STELLA,有人类和小鼠两个版本。由于市面上现有单细胞转录组大模型数量太多(Geneformer,scGPT,scFoundation,LangCell,Cell2Sentence等),这个模型预感可能发表不出去了😢。这个项目就当做自己的一个练手项目吧……🥲🥲🥲。整个训练流程完全基于huggingface生态进行开发,数据集构建采用datasets模块,模型训练使用transformers的Trainer,自己也是第一次手搓大模型,也是边学习边写,有些过程还是比较难写的(例如DataCollator等),自己也debug了很多代码,学习了很多huggingface代码工程化思想,收益很多。虽然模型可能发表不出去了,但是整个仓库代码个人认为写的还是比较清晰的(某中科院大佬点赞称比已经发表的大模型代码好读很多~😂(bushi)),适合刚入门大模型的同学学习提升自己的代码能力,熟悉整个构建流程。 [Read More] Tags: huggingface scRNA LLM
attention_mask 🫥 encoder- and decoder-only standard attention_mask By Pengpeng Wu Posted on May 9, 2025 🚅 看了一下huggingface官方是怎么写标准的encoder-only和decoder-only的attention_mask的,写的还是非常有意思的~ [Read More] Tags: huggingface
tie_weights 😪 开工开工! By Pengpeng Wu Posted on May 6, 2025 🙂 疯狂工作的一天!看了一下transformers是如何实现权重绑定的! [Read More] Tags: huggingface
self.loss_function 😢 The holiday is over By Pengpeng Wu Posted on May 6, 2025 🙂 最近看Qwen3模型的时候,发现transformers在模型的forward中直接调用了self.loss_function,但在init初始化时并没有显式添加这一属性,猜测huggingface团队可能对loss进行了统一和封装,于是就详细探索了一下~ [Read More] Tags: huggingface
PPO 🤖 RLHF By Pengpeng Wu Posted on May 1, 2025 🎈 接上篇,大语言模型在经历SFT和训练Reward Model后,后面一个阶段就是开始PPO强化学习,这样就完成了整个RLHF过程。本节将从工程化视角解读trl是如何实现PPO强化学习的~ [Read More] Tags: huggingface RL
Train Reward Model ✈️ 保持热爱,奔赴山海 ~ By Pengpeng Wu Posted on April 27, 2025 🎈 本节将解读如何使用trl训练一个Reward Model [Read More] Tags: huggingface RL
TensorParallel 🌻 美丽的花虽然会凋谢,可是盛开的时刻值得欣赏 ~ By Pengpeng Wu Posted on April 14, 2025 🤖 本节将解读Huggingface是如何实现张量并行(TP)的~ [Read More] Tags: huggingface TP
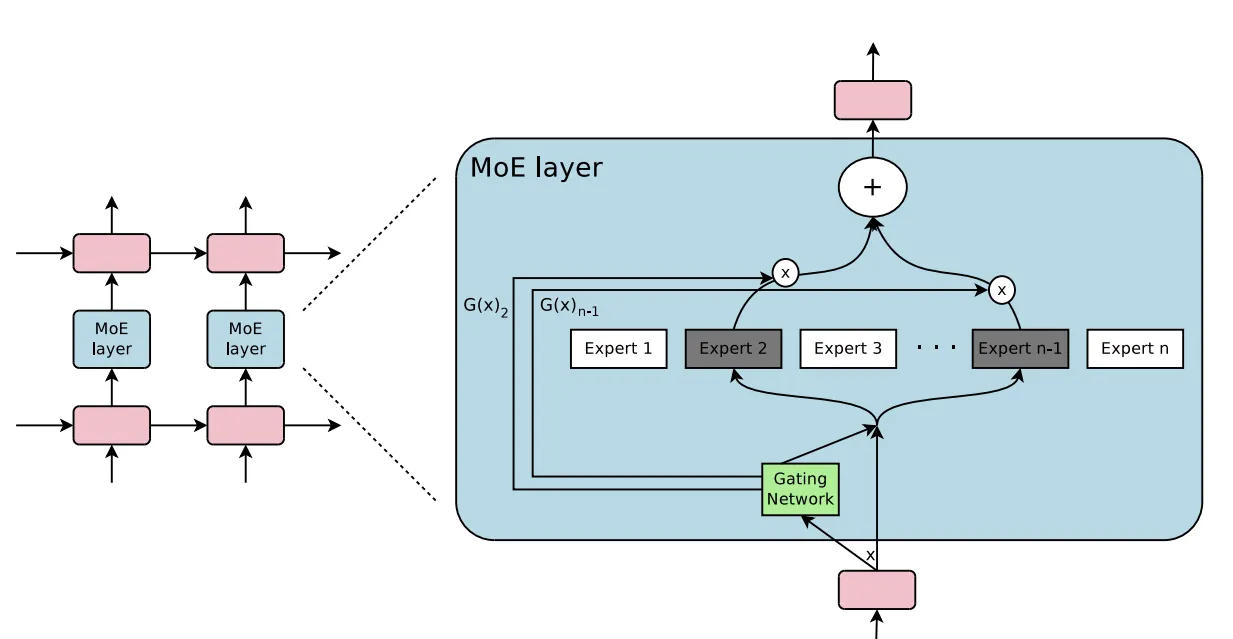
MixtralSparseMoeBlock 🥰 在心里种花,人生才会不荒芜 ~ By Pengpeng Wu Posted on December 9, 2024 🐒 最近看了Mixtral是如何实现MoE的,发现代码写的是真的简洁优雅,下面来详细解读一下~ [Read More] Tags: huggingface MoE