🤖 本节将解读Huggingface是如何实现张量并行(TP)的~
1. TP 简介
- 在张量并行中,线性层的计算可以在GPU之间进行拆分。这样可以节省内存,因为每个GPU只需要保存权重矩阵的一部分。线性层有两种拆分方式:按行和按列。
1.1 Column-wise Parallel
- 在Column-wise Parallel中,权重矩阵按列维度均匀分割。每个GPU都收到相同的输入,并使用其权重矩阵部分计算常规矩阵乘法。最后,每个GPU的输出concat起来形成最终输出。
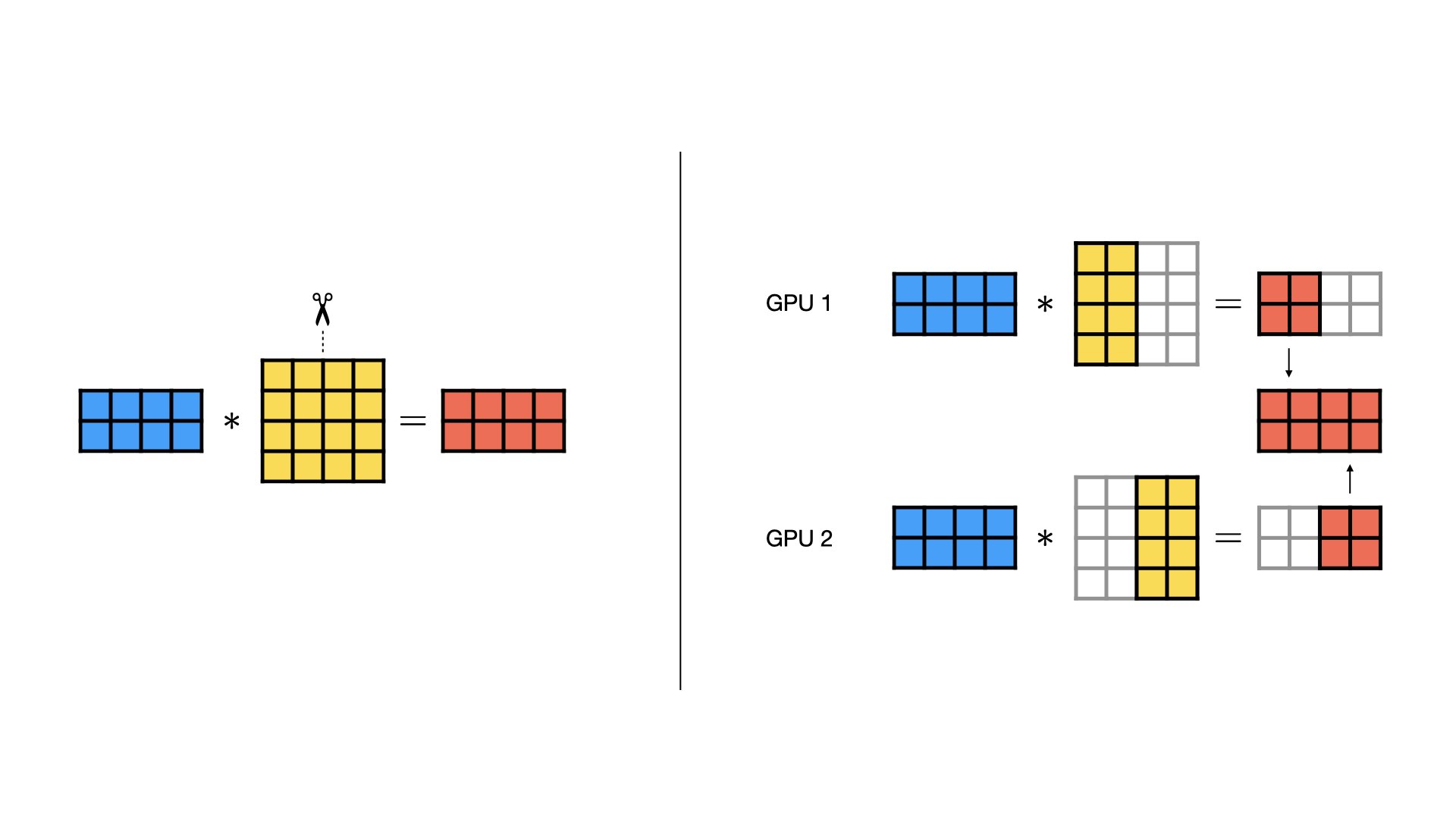
1.2 Row-wise Parallel
- 在Row-wise Parallel中,权重矩阵按行维度均匀分割,此外,输入矩阵也要按照列维度均匀分割。每个GPU收到对应的输入和权重矩阵,并进行矩阵乘法。最后,每个GPU的输出相加形成最终输出。
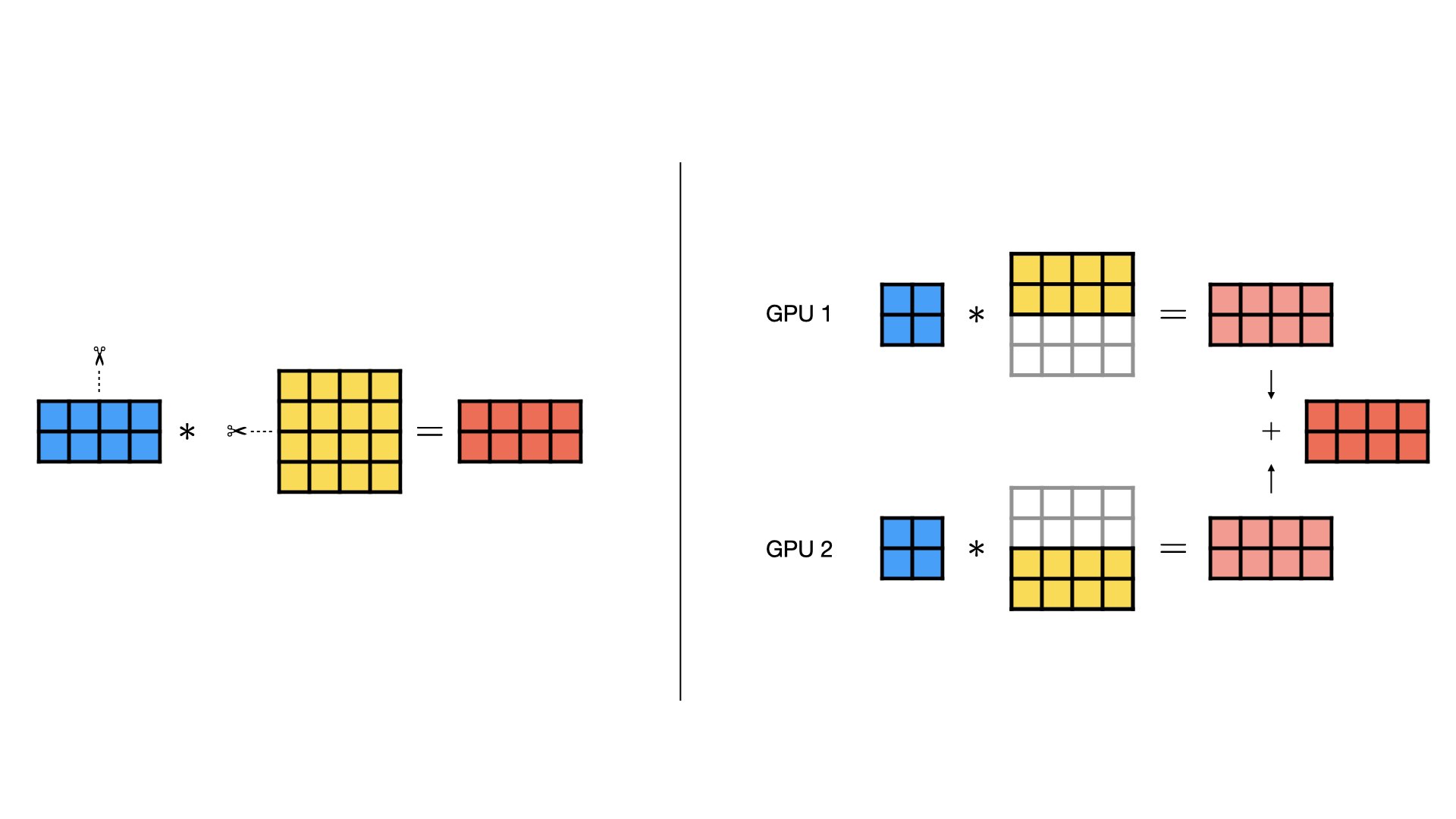
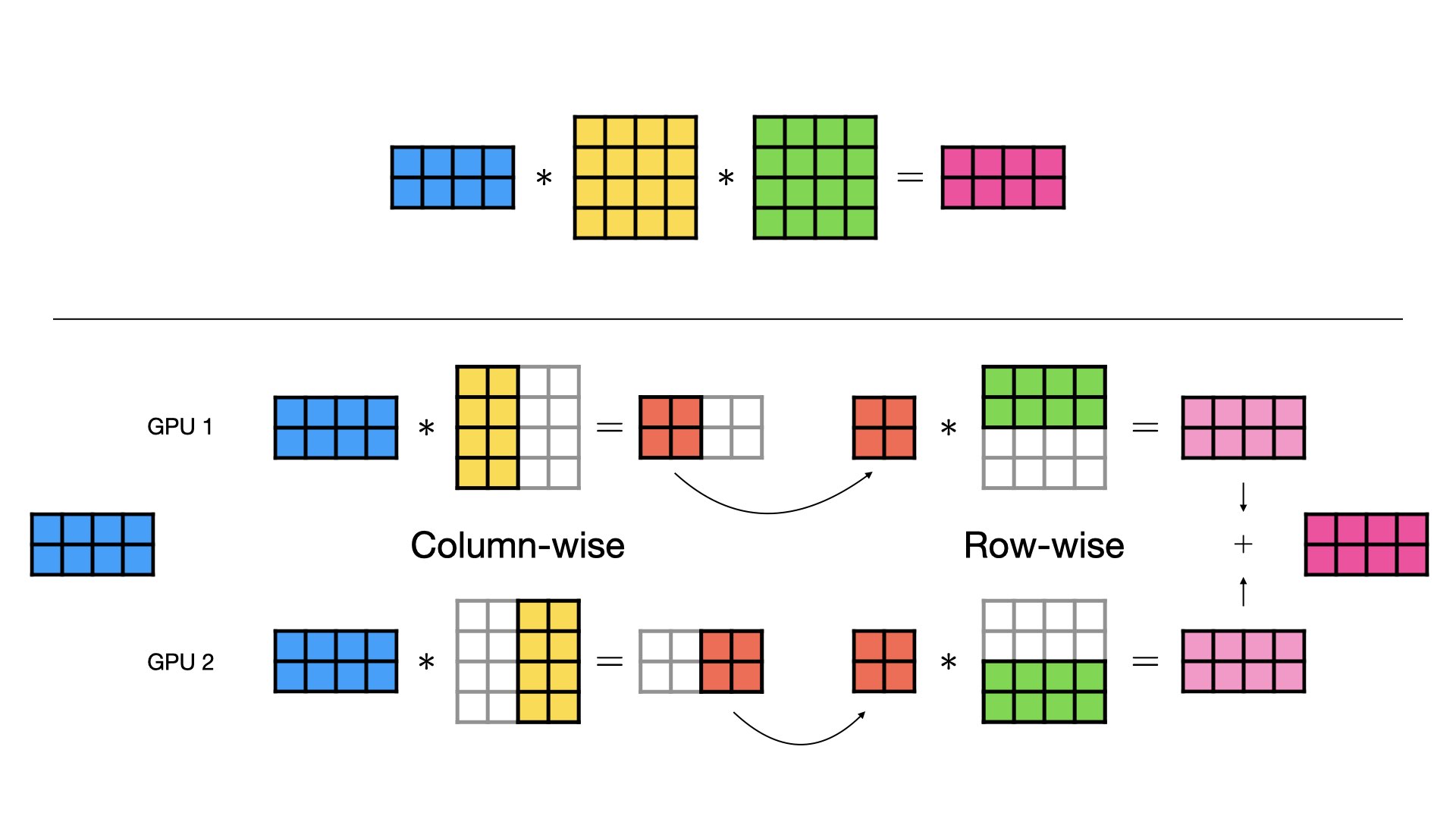
1.3 Combined Column- and Row-wise Parallel
- Column-wise Parallel 和 Row-wise Parallel 主要应用于 Y=XW 这种只有两个矩阵相乘的情况,当有3个或多个矩阵相乘时,我们可以结合这两种分割方式以获得最佳效果。
2. 代码实现
- 在LLM中,通常会为MLP层和Attention层实现TP
- 但是,需要注意的是,huggingface的transformers实现的TP,只是降低了单个矩阵计算的大小,并没有把各个矩阵分片到不同的显卡上,如果需要解决这个问题,需要改一下代码,分配权重所在设备
2.1 MLP
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
if self.config.pretraining_tp > 1:
slice = self.intermediate_size // self.config.pretraining_tp
gate_proj_slices = self.gate_proj.weight.split(slice, dim=0)
up_proj_slices = self.up_proj.weight.split(slice, dim=0)
down_proj_slices = self.down_proj.weight.split(slice, dim=1)
gate_proj = torch.cat(
[F.linear(x, gate_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1
)
up_proj = torch.cat([F.linear(x, up_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1)
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)
down_proj = [
F.linear(intermediate_states[i], down_proj_slices[i]) for i in range(self.config.pretraining_tp)
]
down_proj = sum(down_proj)
else:
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj
- 在LlamaMLP中,官方实现是对gate_proj和up_proj的权重进行了列分割,对down_proj的权重进行了行分割,并未采用混合分割的方式。
2.3 Attention
class LlamaAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: LlamaConfig):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.max_position_embeddings = config.max_position_embeddings
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
self._init_rope()
def _init_rope(self):
if self.config.rope_scaling is None:
self.rotary_emb = LlamaRotaryEmbedding(self.head_dim, max_position_embeddings=self.max_position_embeddings)
else:
scaling_type = self.config.rope_scaling["type"]
scaling_factor = self.config.rope_scaling["factor"]
if scaling_type == "linear":
self.rotary_emb = LlamaLinearScalingRotaryEmbedding(
self.head_dim, max_position_embeddings=self.max_position_embeddings, scaling_factor=scaling_factor
)
elif scaling_type == "dynamic":
self.rotary_emb = LlamaDynamicNTKScalingRotaryEmbedding(
self.head_dim, max_position_embeddings=self.max_position_embeddings, scaling_factor=scaling_factor
)
else:
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
if self.config.pretraining_tp > 1:
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
query_slices = self.q_proj.weight.split(
(self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
)
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
query_states = torch.cat(query_states, dim=-1)
key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
key_states = torch.cat(key_states, dim=-1)
value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
value_states = torch.cat(value_states, dim=-1)
else:
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
kv_seq_len = key_states.shape[-2]
if past_key_value is not None:
kv_seq_len += past_key_value[0].shape[-2]
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
if past_key_value is not None:
# reuse k, v, self_attention
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
past_key_value = (key_states, value_states) if use_cache else None
# repeat k/v heads if n_kv_heads < n_heads
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
raise ValueError(
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
f" {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights + attention_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
if self.config.pretraining_tp > 1:
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
else:
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
- 在LlamaAttention中,实现TP的部分主要包含:
- 生成QKV矩阵时:均对权重矩阵采取列分割
- 最后一个全连接输出层:采用行分割,对attn_output进行列分割,对权重矩阵进行行分割
Note: 需要注意的是,nn.Linear(a, b),其对应的权重矩阵形状是(b, a), 在进行列分割时,我们需要在b维度(dim=0)进行分割;在进行行分割时,我们需要在a维度(dim=-1)进行分割,不要搞错分割的维度~🤗