🎈 本节将解读如何使用trl训练一个Reward Model
- 参考代码:https://github.com/huggingface/trl/blob/main/examples/scripts/reward_modeling.py
- transformers:4.49.0; trl: 0.17.0
1. Dataset Overview
- 数据集使用的是Huggingface: trl-lib/ultrafeedback_binarized
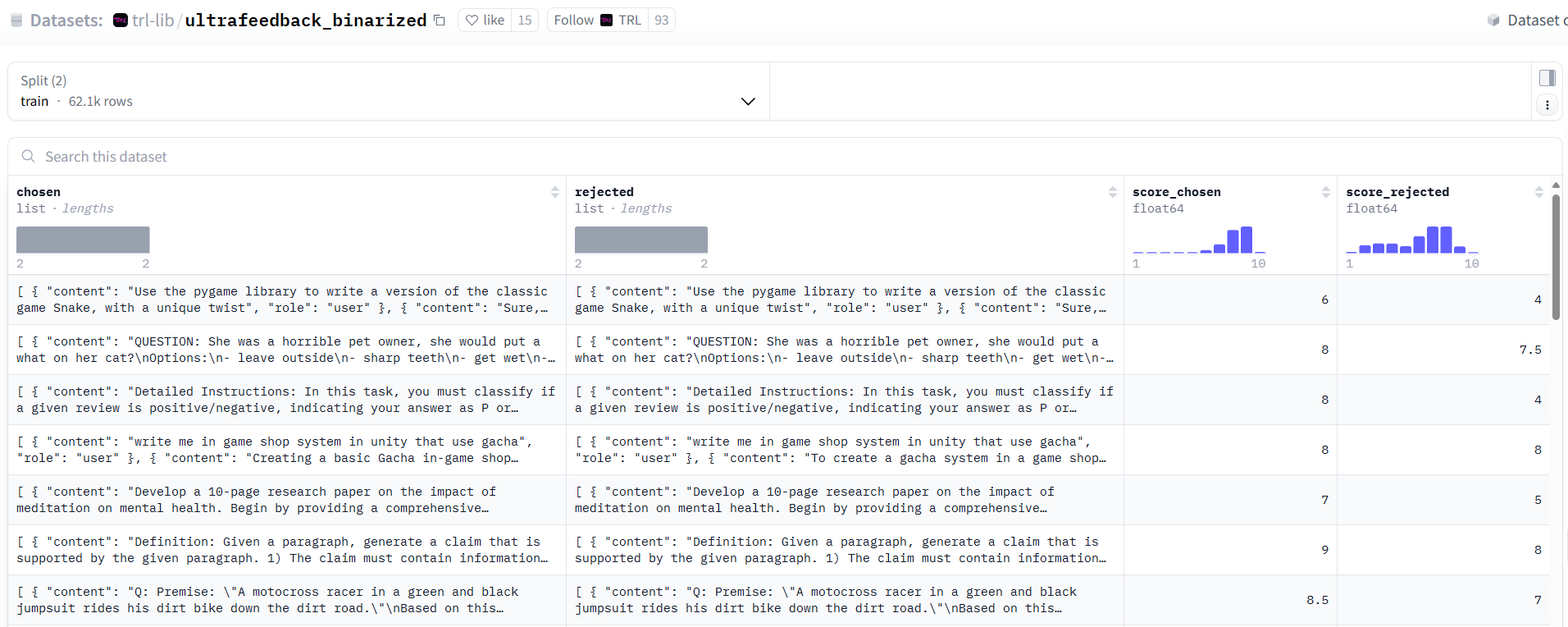
- 如下图,数据集总共包含四个字段:
- chosen:满意的问答。每一个样本存储格式为[{‘content’: ‘…’, ‘role’: ‘user’}, {‘content’: ‘…’, ‘role’: ‘assistant’}],列表中的第一个字典存储的是用户的提问,第二个字典存储的是模型的回答
- rejected:不满意的问答。样本存储格式同chosen
- score_chosen:给chosen中每个问答打的分
- score_rejected:给rejected中每个问答打的分
2. Process Dataset
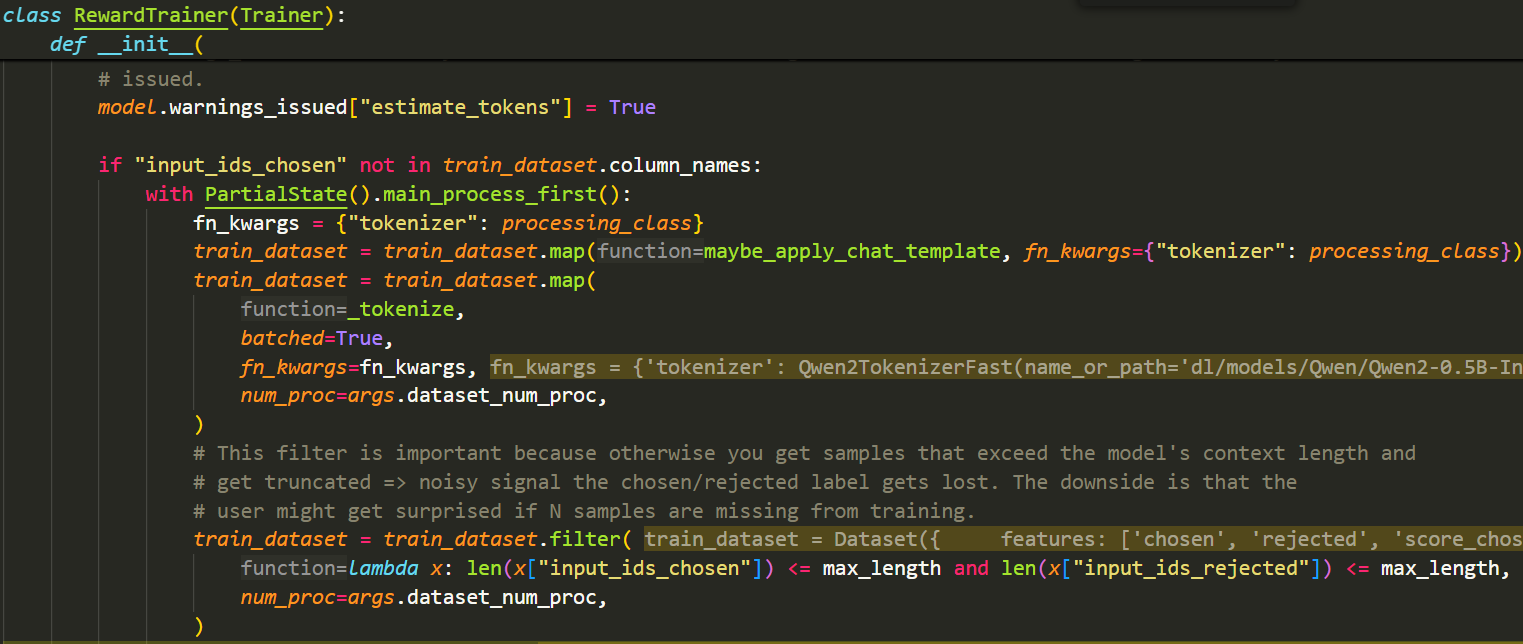
- 在Huggingface的RewardTrainer中,数据集中的每个问答会被拼接在一起,形成一个长字符串:

- 接下来,使用tokenizer对拼接后的chosen和rejected字符串进行tokenize。对于每一个样本,除了保留原本的四个字段外,还会产生四个新的字段:input_ids_chosen,attention_mask_chosen,input_ids_rejected,attention_mask_rejected
- 最后,一个很重要的处理部分,我们只保留input_ids_chosen和input_ids_rejected都小于等于max_length的样本,以防止截断文本造成信号丢失和引入噪声,导致模型无法正确学习chosen/rejected标签的区分
- 具体源码如下:
3. Model
- 模型使用的是:AutoModelForSequenceClassification,其中num_labels设置成1

4. Compute Loss
- 接下来是最重要的部分,模型是如何计算损失的:
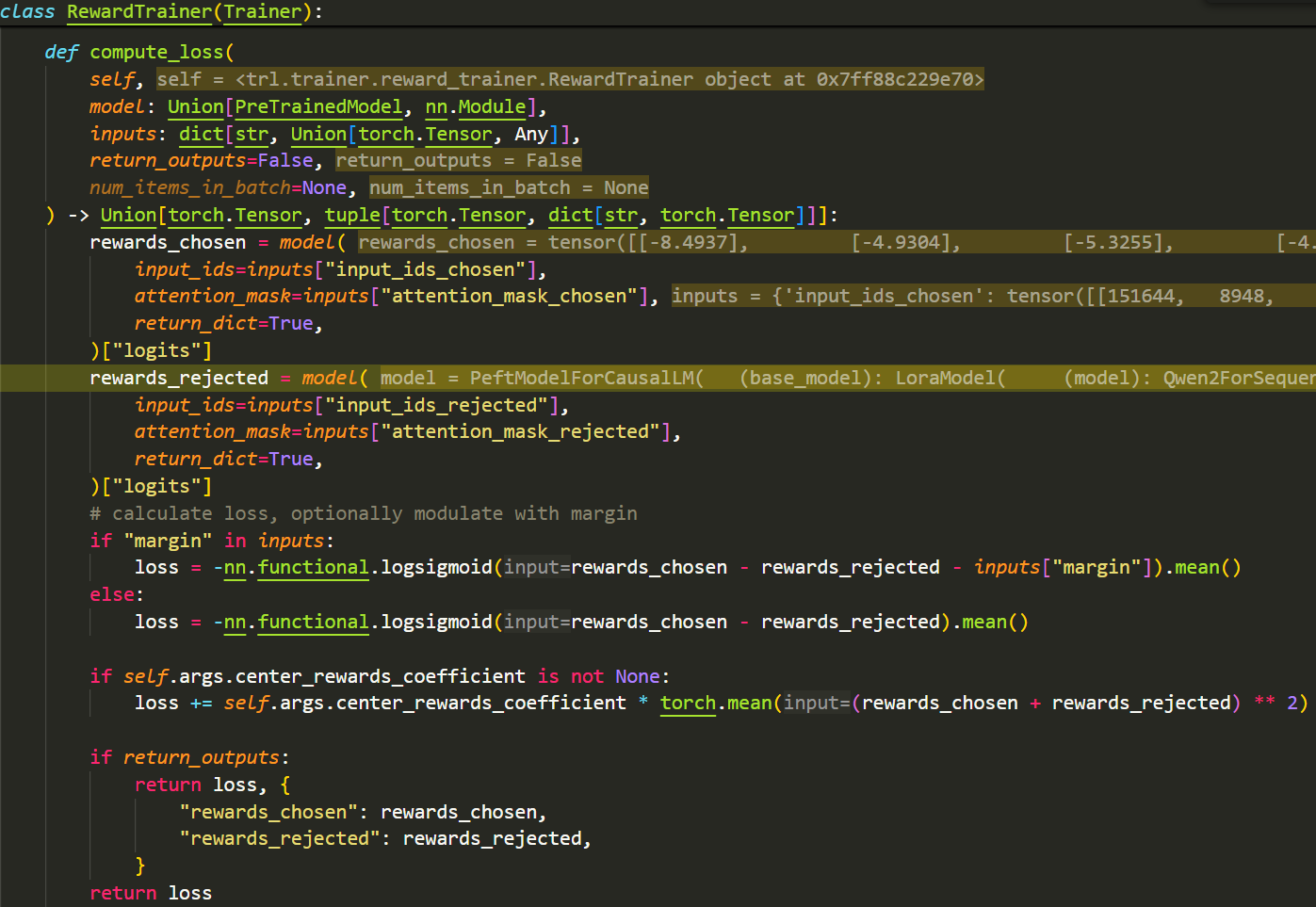
- 首先,每个样本的chosen和rejected会分别传递给模型,拿到模型输出的logits (batch_size, 1)
- 以Qwen2为例,我们可以看一下它输出的logits是什么:
- Qwen2ForSequenceClassification模型会首先输出hidden_states (batch_size, seq_len, hidden_size),接着会经过分类头输出logits (batch_size, seq_len, 1),最后,对于每一个样本,Qwen2会选择最后一个非pad token的logits作为该样本最终的logits (batch_size, 1)
- 最终输出的logits就可以认为是Reward Model给每个回答打的分
- 然后就是计算loss的部分:loss = -nn.functional.logsigmoid(rewards_chosen - rewards_rejected).mean(),让模型学会区分更优的回答和次优的回答
🎈到这里,整个Reward Model是如何训练的就已经非常清楚了,主要就是数据集的处理以及loss的计算~