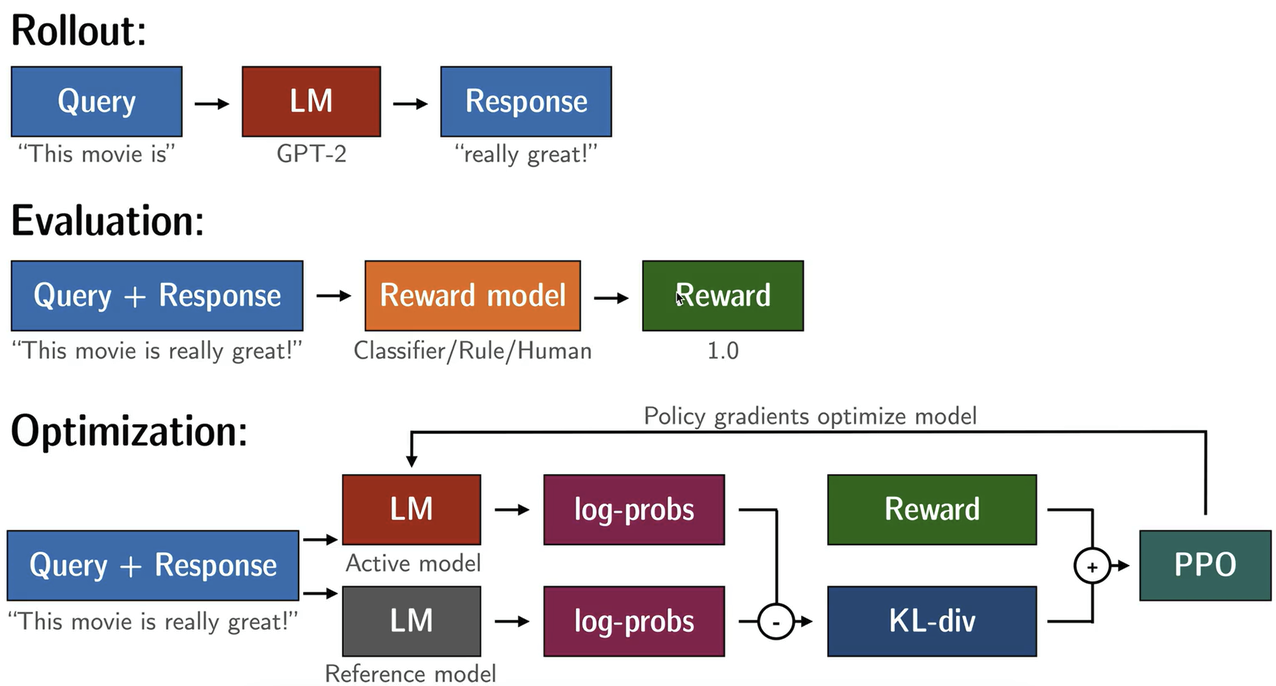
🎈 接上篇,大语言模型在经历SFT和训练Reward Model后,后面一个阶段就是开始PPO强化学习,这样就完成了整个RLHF过程。本节将从工程化视角解读trl是如何实现PPO强化学习的~
- 参考代码:https://github.com/huggingface/trl/blob/main/examples/scripts/ppo/ppo.py
- transformers:4.49.0; trl: 0.17.0
1. Dataset
- 数据集方面,我们只需要准备Query即可,不需要完整的问答数据
2. Model
- 我们一共需要四个模型:
- Policy Model: 使用SFT后的模型初始化,需要更新参数
- Reference Policy Model: 使用SFT后的模型初始化,不需要更新参数
- Reward Model: 使用Reward Model初始化,不需要更新参数
- Value Model: 使用Reward Model初始化,需要更新参数
3. Workflow
- 注意:在正式进入PPO算法训练之前,以下的所有的步骤都是不要更新梯度的!
3.1 Step 1
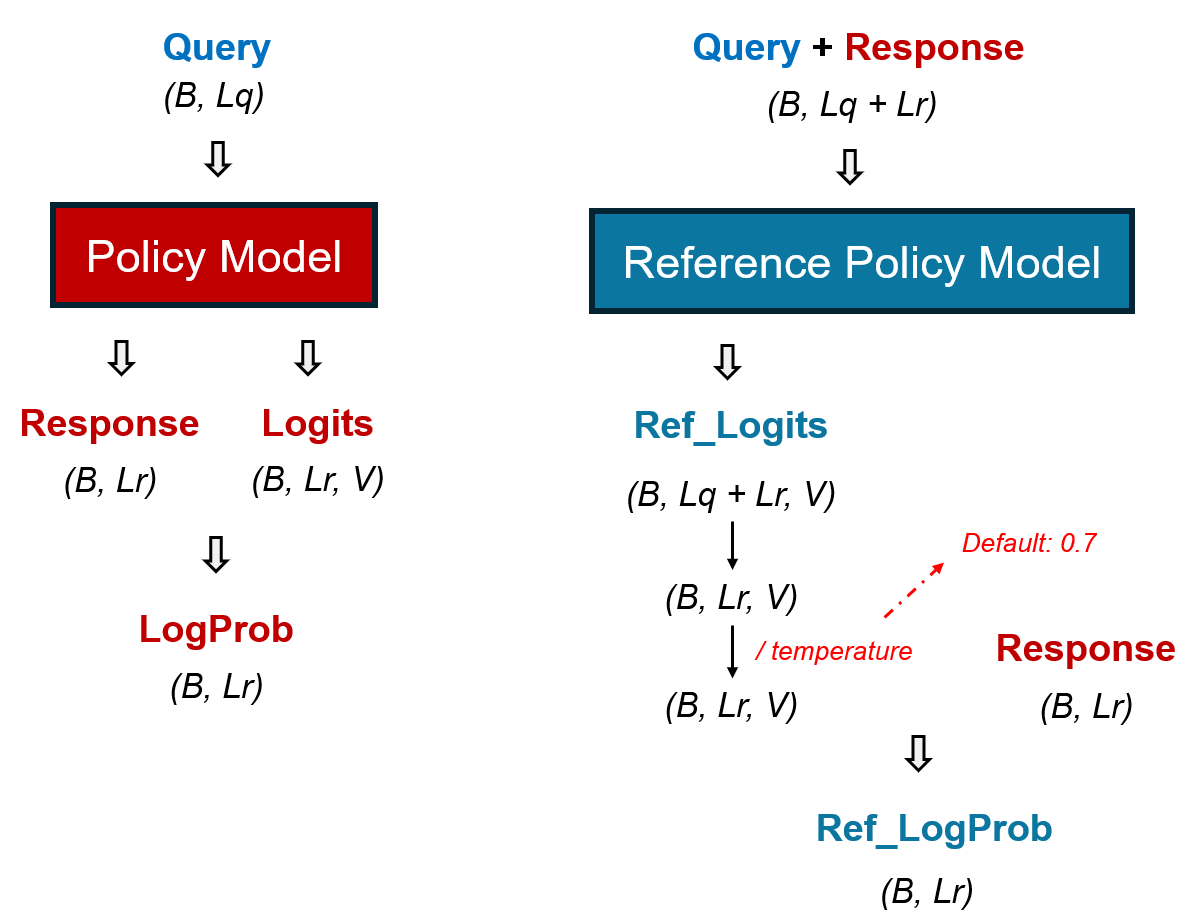
- 首先,我们需要从Dataset中取出一个batch的query,将其传入Policy Model,得到相应的response和logits,这个过程就是在让Policy Model根据query生成回答,生成回答的最大长度我们需要在配置文件中指定好,生成的回答如果没有达到最大长度(即:遇到eos token,提前终止生成),我们用pad token填充,logits我们用0填充;得到response和logits后,我们就可以计算logprob
- 但是,需要特别注意的是,配置文件中设置了early_stopping=False,因此,即使遇到了终止符,还是会继续生成到最大长度,并没有进行填充
- 接着,我们需要将query和response拼接在一起,传入Reference Policy Model,输出ref_logits,我们取response部分的logits,除以一个temperature(default: 0.7)系数,然后联合response,计算ref_logprob
- 具体计算log_prob和ref_logprob的函数如下:
def selective_log_softmax(logits, index):
"""
A memory-efficient implementation of the common `log_softmax -> gather` operation.
This function is equivalent to the following naive implementation:
```python
logps = torch.gather(logits.log_softmax(-1), dim=-1, index=index.unsqueeze(-1)).squeeze(-1)
Args:
logits (`torch.Tensor`):
Logits tensor of shape `(..., num_classes)`.
index (`torch.Tensor`):
Index tensor of shape `(...)`, specifying the positions to gather from the log-softmax output.
Returns:
`torch.Tensor`:
Gathered log probabilities with the same shape as `index`.
"""
if logits.dtype in [torch.float32, torch.float64]:
selected_logits = torch.gather(logits, dim=-1, index=index.unsqueeze(-1)).squeeze(-1)
# loop to reduce peak mem consumption
logsumexp_values = torch.stack([torch.logsumexp(lg, dim=-1) for lg in logits])
per_token_logps = selected_logits - logsumexp_values # log_softmax(x_i) = x_i - logsumexp(x)
else:
# logsumexp approach is unstable with bfloat16, fall back to slightly less efficent approach
per_token_logps = []
for row_logits, row_labels in zip(logits, index): # loop to reduce peak mem consumption
row_logps = F.log_softmax(row_logits, dim=-1)
row_per_token_logps = row_logps.gather(dim=-1, index=row_labels.unsqueeze(-1)).squeeze(-1)
per_token_logps.append(row_per_token_logps)
per_token_logps = torch.stack(per_token_logps)
return per_token_logps
3.2 Step 2
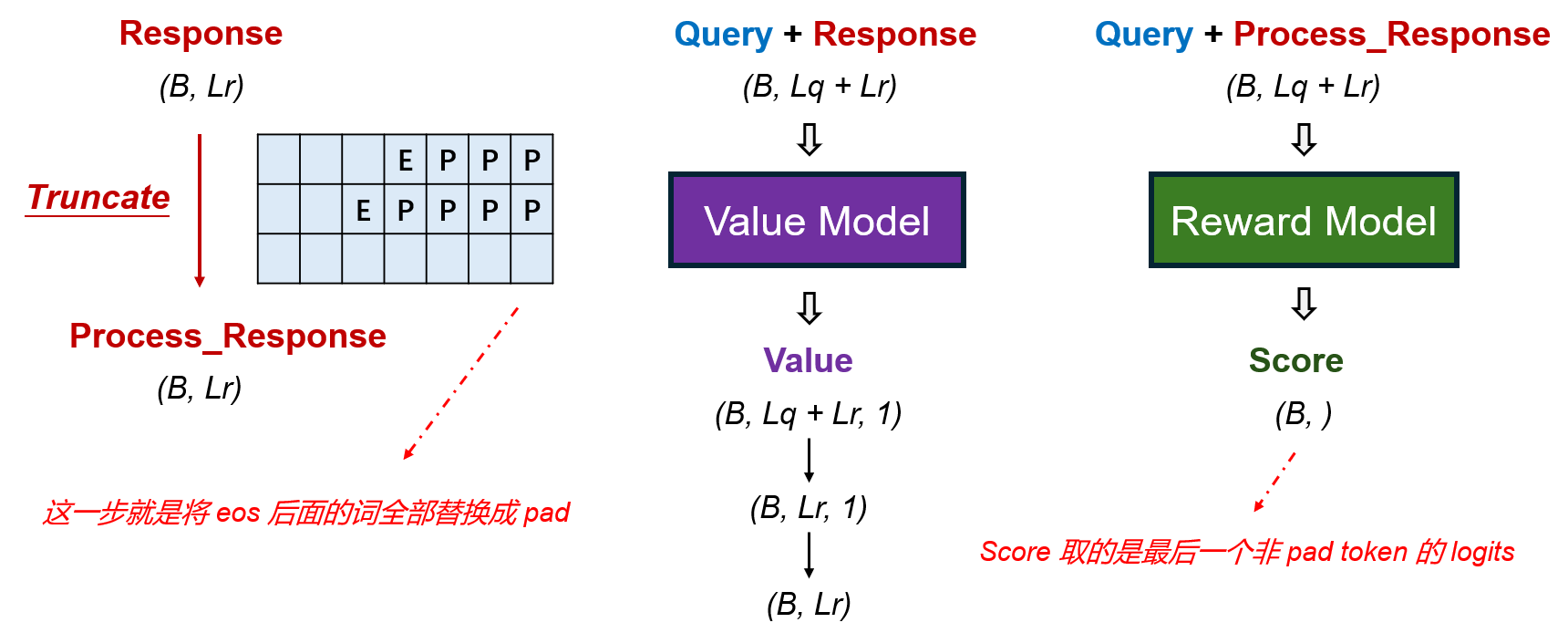
- Truncate操作是为了应对一些边缘情况,此处我暂时没有看懂,示例代码中response = process_response,并没有进行Truncate这一操作,此处先这样简单理解
- 将query和response拼接在一起,传入Value Model,得到value,取response部分的value,即可得到最终的value
- 将query和process_response拼接在一起,传入Reward Model,得到score,理论上,我们得到的score形状应该是(B,Lq + Lr),这里的形状是(B,),因为每个样本我们取的是最后一个非pad token的logits;由于没有Truncate和pad操作,因此取的就是最后一个token的logits
- value和score的计算用的是同一个函数:
def get_reward(
model: torch.nn.Module, query_responses: torch.Tensor, pad_token_id: int, context_length: int
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Computes the reward logits and the rewards for a given model and query responses.
Args:
model (`torch.nn.Module`):
The model used to compute the reward logits.
query_responses (`torch.Tensor`):
The tensor containing the query responses.
pad_token_id (`int`):
The token ID representing the pad token.
context_length (`int`):
The length of the context in the query responses.
Returns:
tuple:
- `reward_logits` (`torch.Tensor`):
The logits for the reward model.
- `final_rewards` (`torch.Tensor`):
The final rewards for each query response.
- `sequence_lengths` (`torch.Tensor`):
The lengths of the sequences in the query responses.
"""
attention_mask = query_responses != pad_token_id
position_ids = attention_mask.cumsum(1) - attention_mask.long() # exclusive cumsum
lm_backbone = getattr(model, model.base_model_prefix)
input_ids = torch.masked_fill(query_responses, ~attention_mask, 0)
output = lm_backbone(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
return_dict=True,
output_hidden_states=True,
use_cache=False, # otherwise mistral-based RM would error out
)
reward_logits = model.score(output.hidden_states[-1])
sequence_lengths = first_true_indices(query_responses[:, context_length:] == pad_token_id) - 1 + context_length
# https://github.com/huggingface/transformers/blob/dc68a39c8111217683bf49a4912d0c9018bab33d/src/transformers/models/gpt2/modeling_gpt2.py#L1454
return (
reward_logits, # 所有token的logits, 形状为(batch_size, qa_len, 1)
reward_logits[
torch.arange(reward_logits.size(0), device=reward_logits.device),
sequence_lengths,
].squeeze(-1), # 取最后一个非pad token的logits, 形状为(batch_size,)
sequence_lengths, # 每个qa, 最后一个非pad token的index, 形状为(batch_size,)
)
3.3 Step 3
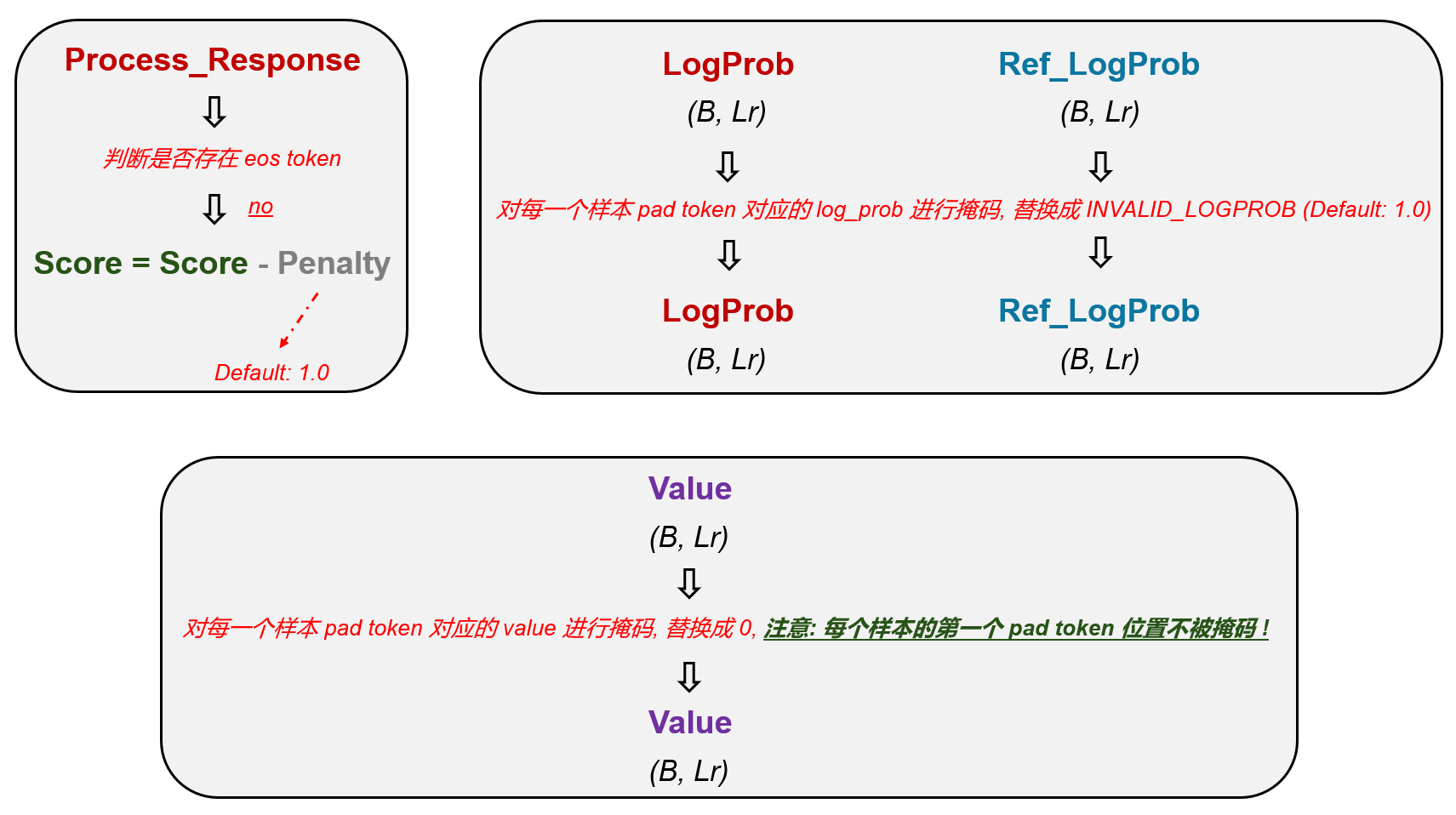
- Step 2中我们得到了Reward Model产生的score,我们还需要根据每个样本是否包含eos token对分数进一步进行调整,如果不包含eos token,我们需要对相应样本的score罚分,默认罚1分
- 接下来是一些掩码的操作:
- logprob和ref_logprob需要对pad token的位置进行掩码,并替换成INVALID_LOGPROB: 1.0
- value需要对pad token的位置进行掩码,并替换成0,并且第一个pad token的位置不会被掩码
- 这里也是只有进行了Truncate操作,这里的掩码才会生效,因为他是根据process_response中pad token的位置来进行掩码的
3.4 Step 4
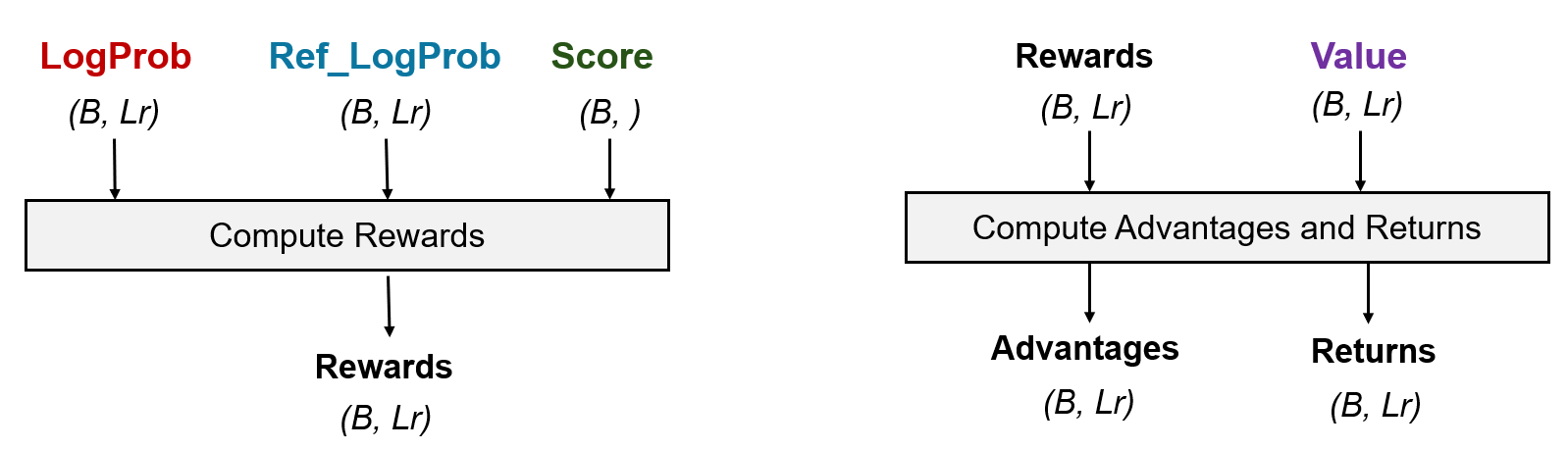
- 最后,我们需要根据logprob和ref_logprob计算kl散度,然后与score相加得到rewards
- 同样的,我们也需要根据rewards和value计算得到advantages和returns
- 这里就是一些数学上的操作,相关的代码如下:(详细过程请进入源码查看)
def masked_whiten(values: torch.Tensor, mask: torch.Tensor, shift_mean: bool = True) -> torch.Tensor:
"""Whiten values with masked values."""
mean, var = masked_mean(values, mask), masked_var(values, mask)
whitened = (values - mean) * torch.rsqrt(var + 1e-8)
if not shift_mean:
whitened += mean
return whitened
# 4. compute rewards
# Formula used by http://joschu.net/blog/kl-approx.html for the k1 and k3 estimators
logr = ref_logprobs - logprobs
kl = -logr if args.kl_estimator == "k1" else (logr.exp() - 1) - logr # Else statement is k3
non_score_reward = -args.kl_coef * kl
rewards = non_score_reward.clone()
actual_start = torch.arange(rewards.size(0), device=rewards.device)
actual_end = torch.where(sequence_lengths_p1 < rewards.size(1), sequence_lengths_p1, sequence_lengths)
rewards[[actual_start, actual_end]] += scores
# 5. whiten rewards
if args.whiten_rewards:
rewards = masked_whiten(rewards, mask=~padding_mask_p1, shift_mean=False)
rewards = torch.masked_fill(rewards, padding_mask_p1, 0)
# 6. compute advantages and returns
lastgaelam = 0
advantages_reversed = []
gen_length = responses.shape[1]
for t in reversed(range(gen_length)):
nextvalues = values[:, t + 1] if t < gen_length - 1 else 0.0
delta = rewards[:, t] + args.gamma * nextvalues - values[:, t]
lastgaelam = delta + args.gamma * args.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], axis=1)
returns = advantages + values
advantages = masked_whiten(advantages, ~padding_mask)
advantages = torch.masked_fill(advantages, padding_mask, 0)
torch.cuda.empty_cache()
至此,所有的数据准备阶段就完成了,后面就正式进入了PPO优化过程,就是一些计算loss,反向传播的过程~
- 由于本人是做生物信息学的,平时只粗浅的了解过一些强化学习的基本理论,学习PPO的代码也只是想了解一下他整个的数据流向是如何进行的,如果对代码解读有误,还请大家多多指正~😊
- 最后,附上整个流程的简明示意图: