🙂 疯狂工作的一天!看了一下transformers是如何实现权重绑定的!
-
transformers:4.51.3
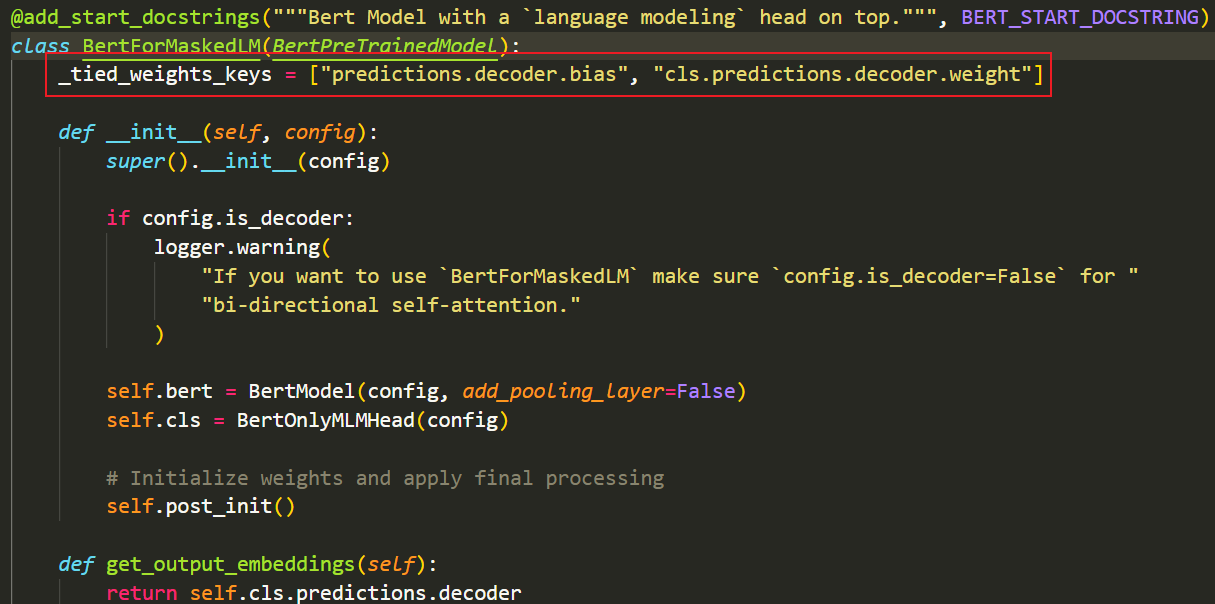
- 以BertForMaskedLM为例,权重绑定的操作其实藏在init方法中的self.post_init()中
- 函数执行顺序:self.post_init() –> self.init_weights() –> self.tie_weights() –> self._tie_or_clone_weights()
- self.tie_weights()和self._tie_or_clone_weights()执行了真正的权重绑定逻辑,让我们来看一下这些方法:
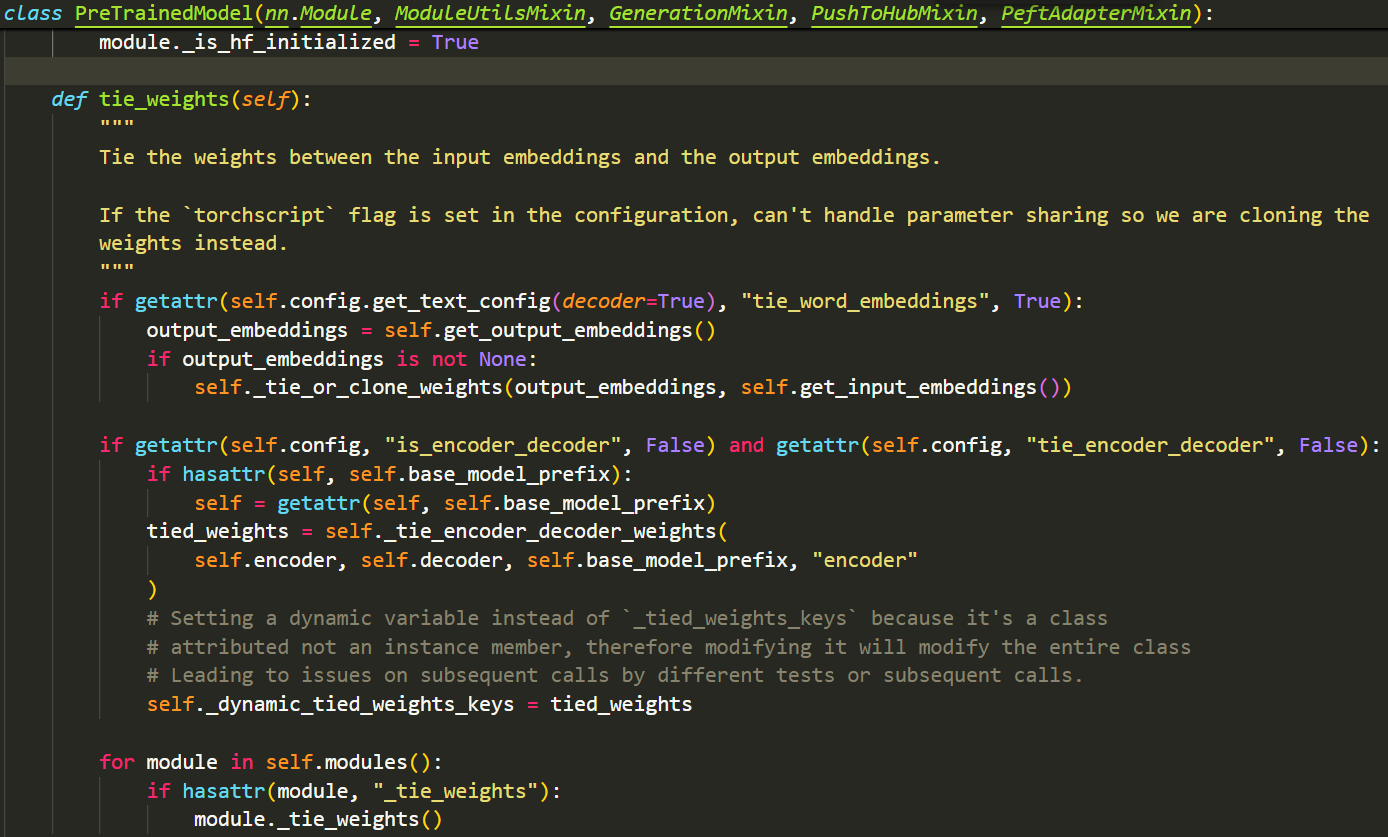
- self.tie_weights()中有三个关键方法,self.get_output_embeddings(),self.get_input_embeddings()和self._tie_or_clone_weights():
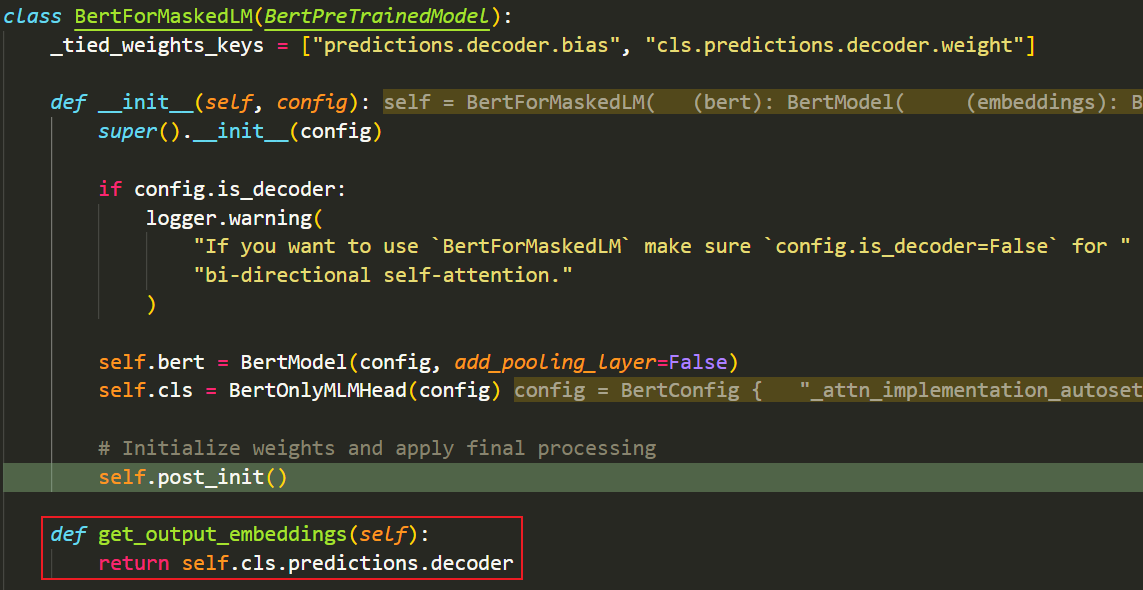
- 首先需要调用self.get_output_embeddings()方法,拿到output_embeddings层,该方法需要我们在BertForMaskedLM中手动重写,以下是官方实现示例:(实际是就是返回了最后一个分类头线性层)
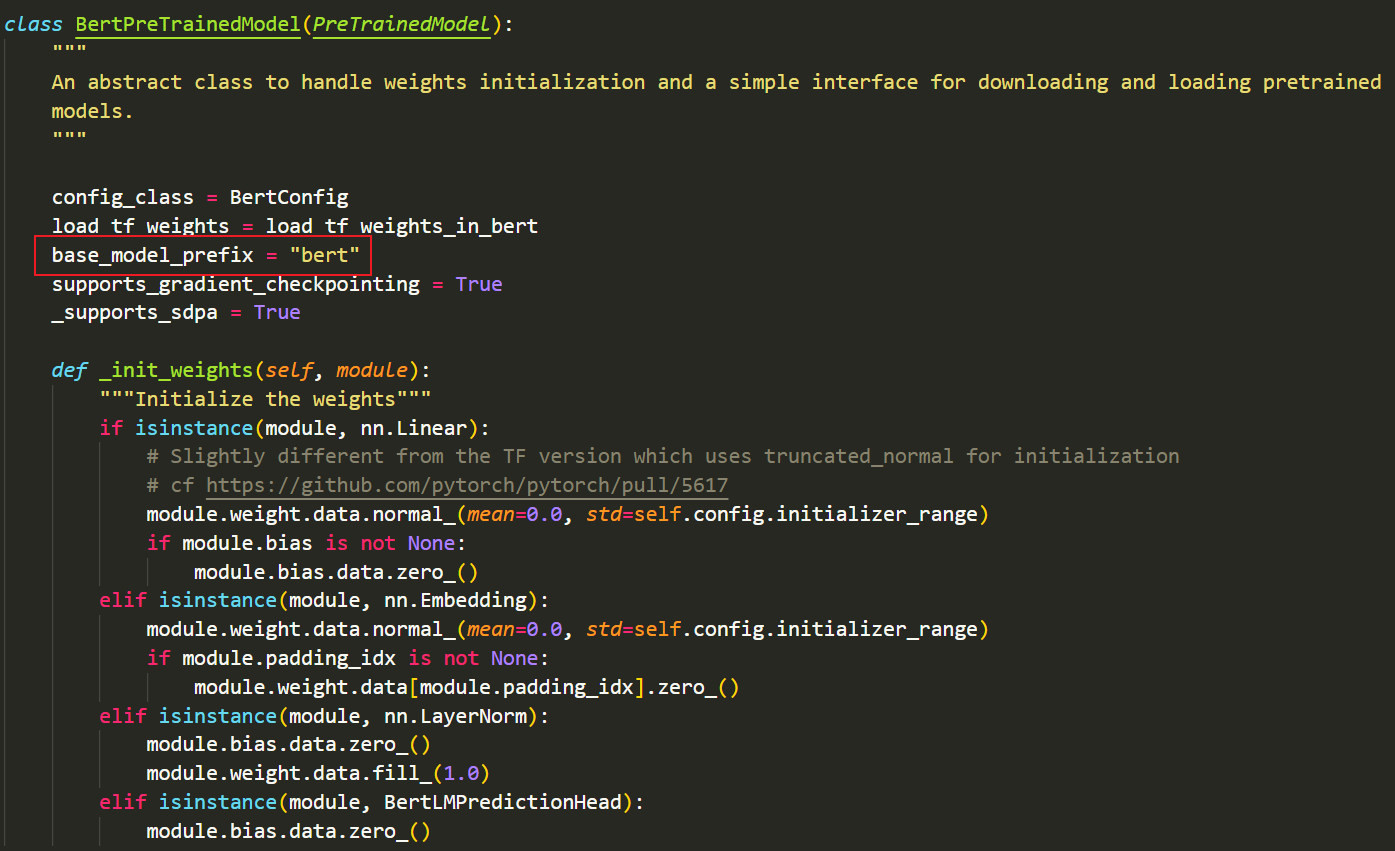
- 接着会调用self.get_input_embeddings()这个方法:(这个方法会根据self.base_model_prefix找到模型的主干部分,然后调用主干模型中的get_input_embeddings()方法,因此,我们需要在主干模型中添加get_input_embeddings()方法,并在用于初始化参数的类中指定类属性base_model_prefix,之所以写在这个类中,是因为后续的所有下游模型都需要继承这个类,这样每个下游模型都能通过self.base_model_prefix访问模型的主干名称)
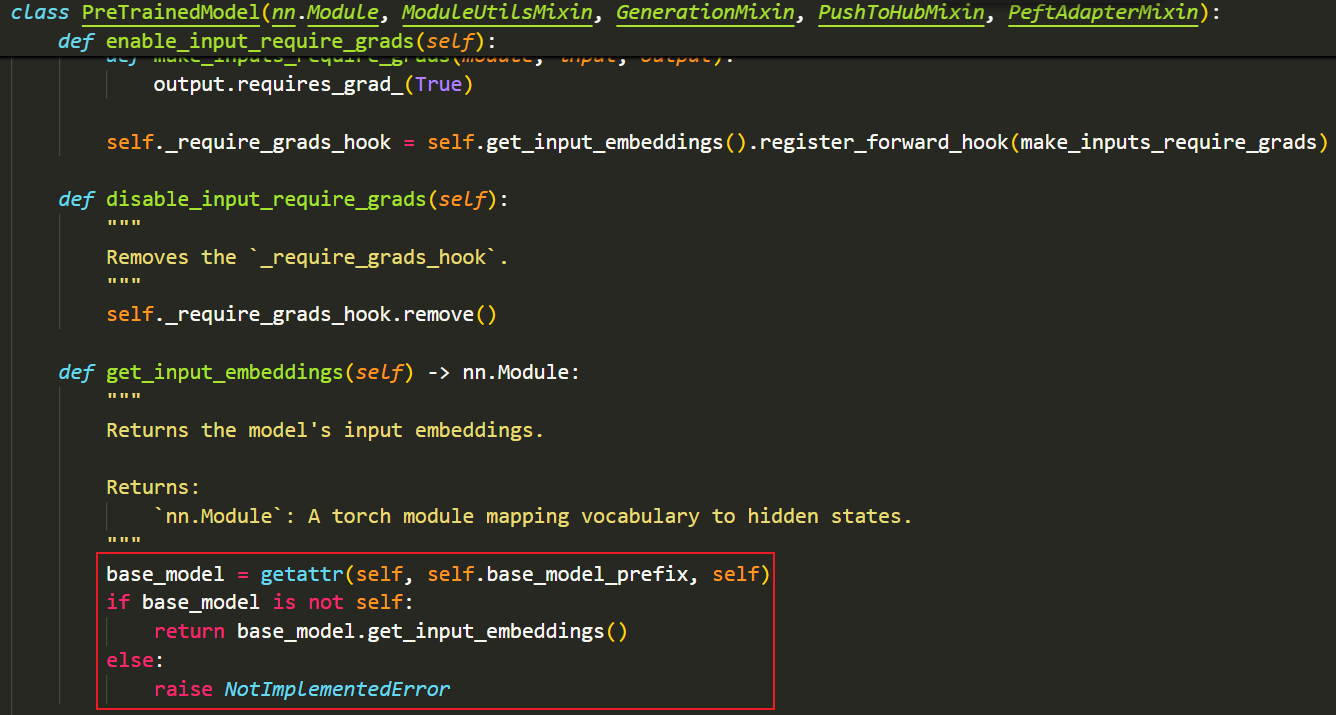
- 以下是官方实现get_input_embeddings()方法的示例:(实际就是返回最开始的nn.Embedding层,可以看到,这个方法被写到了主干模型BertModel中)
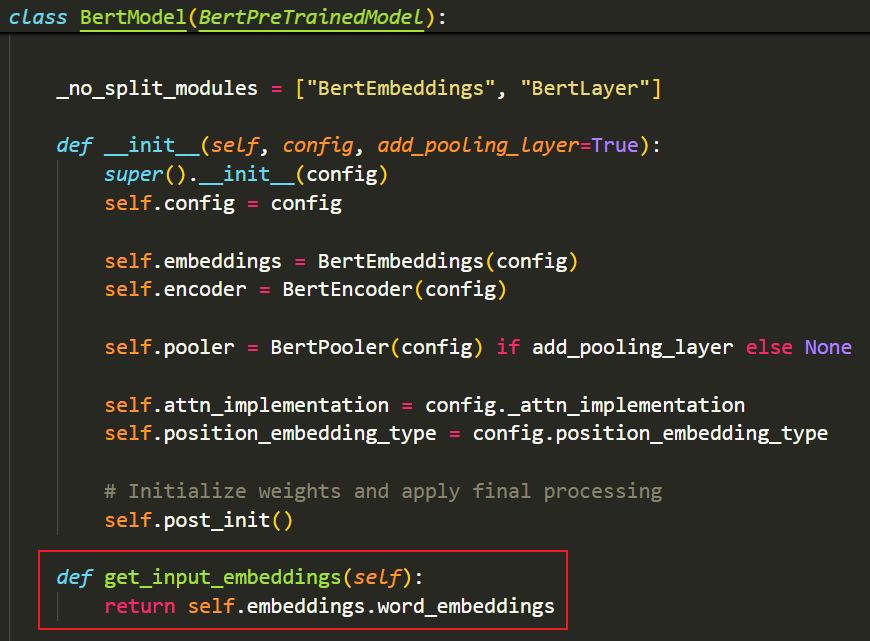
- base_model_prefix被写在了用于初始化参数的类中:
- 最后,我们来看一下self._tie_or_clone_weights()这个方法:
- 其实就是直接将output_embeddings.weight和input_embeddings.weight划等号
- 后面都是一些关于扩充词表的操作,无需关注~
- 到这里,所有的权重绑定操作就完成了,总结一下,需要写三个部分:
- Downstream Model:get_output_embeddings()
- Backbone Model:get_input_embeddings()
- Class for initializing params:类属性 base_model_prefix
- 但是,需要注意的是,如果我们实现了这些方法和属性,在使用transformers时会自动帮我们进行权重绑定,如果不需要权重绑定,我们需要手动在config中设置tie_word_embeddings为False
- 🌻最最最最最后,其实BertForMaskedLM中还写了一个类属性_tied_weights_keys,添加这个属性的作用好像是在调用.save_pretrained()保存模型时,共享参数的模块只保存一份参数,避免保存冗余~